Highway Vehicle Counting in Compressed Domain
last modified : 04-02-2020
General Information
- Title: Highway Vehicle Counting in Compressed Domain
- Authors: X. Liu and Z. Wang and J. Feng and H. Xi
- Link: article
- Date of first submission: June, 2016
- Implementations:
Brief
This article aims to count the number of vehicles in a given highway by using the compressed video (H.264) information, the motion vectors. The main aim of the article is to reduce method complexity compared to others while still being competitive in precision.
How Does It Work
They used a multi-regression method for counting the vehicles. They first create a batch of low-level features which are then used with a Hierarchical Classification based Regression (HCR) to provide the count of vehicles. The whole pipeline is described in the following figure.
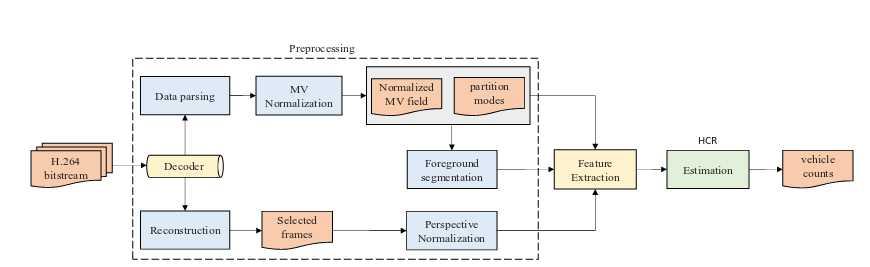
The preprocessing steps (extraction of the low level features) are as follow:
- Normalization of the Motion Vectors (MV): this is mostly to account for the fact that the motion vectors may reference different frames (the earlier the reference frame the bigger the motion vectors)
- Macro-block weighting: because smaller blocks have more chance to represent a car (finer details), they give different weights to favor those smaller blocks
- Foreground segmentation: They extract the motion vectors that are above a given threshold as they should be Foreground
- Perspective normalization: To account for the Perspective in the image, they again add a weights to the blocks (the weights are defined one time per camera through calibration)
Once all of these steps are done the features can be extracted. The extracted features are the following ones:
- Area: "It is defined as the total number of blocks belonging to the segmented foreground"
- Perimeter length: "It is defined as the total number of blocks lying on the perimeter of foreground segment."
- Shape: This is the orientation of the the perimeters blocks
- HOMV (Histogram of Oriented Motion Vector): Similar to shape except for some weights
- Texture: Local binary pattern (LBP)
Finally the HCR is used to predict the count. They used HCR to have a local linear model for prediction by cutting the predictions in groups (c.f article for more details).
Results
Some of the results are shown in the following table. Multiple training strategies are tested, this are the results for one of them: "the samples are randomly split into the training set containing 800 samples and the test set containing 1232 samples as in the classification experiment". See the article for more details on all the experiments.
| Number of training samples | 200 | 300 | 400 | 500 | 600 | 700 | 800 |
|---|---|---|---|---|---|---|---|
| Authors (with all features) | 3.389 | 3.214 | 3.193 | 3.063 | 2.813 | 2.736 | 2.593 |
| Chan et al. | 3.324 | 3.294 | 3.217 | 3.074 | 2.838 | 2.650 | 2.653 |
| Ryan et al. | 3.301 | 3.242 | 3.196 | 3.181 | 3.035 | 2.586 | 2.543 |